Analysis in SPRACE
Available Datasets:
All datasets available in SPRACE (which are AOD or AODSIM) can be found in this link- Single Muon
- Double Electron
- MET
JSON files
JSON files for 2012 Runs at 8 TeV can be found in this linkAnalysis steps
These links should be useful.- https://twiki.cern.ch/twiki/bin/view/CMSPublic/WorkBookCollisionsDataAnalysis

- https://twiki.cern.ch/twiki/bin/view/CMS/Collisions2010Recipes
- https://twiki.cern.ch/twiki/bin/view/CMS/Collisions2011Analysis
- https://twiki.cern.ch/twiki/bin/view/CMS/PdmV2012Analysis
Online list of runs, triggers, etc.
General Analysis Strategy
In general, we advocate the following strategy:- Download datasets to SPRACE (optional)
- Skim on basic reconstructed quantities // trigger bits. Run on GRID with CRAB. Save at SPRACE
- Make Pattuples contataining everything you need for your analysis. Run on these using Condor. Save at SPRACE
- Make basic ROOT ntuples containing very basic information for optimization // plots. Run on these at the interactive access server and/or your laptop.
Skimming
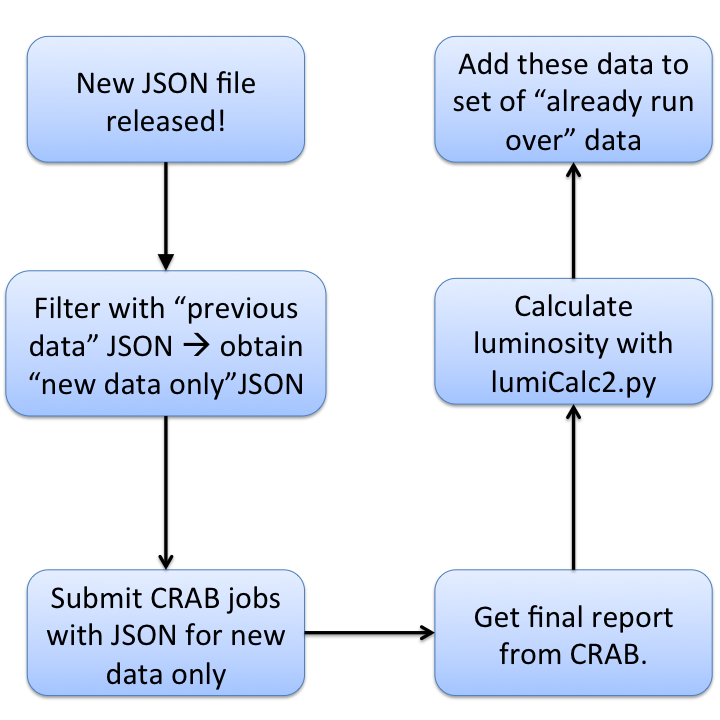
- Get the most recent JSON file for the link above
- If you have already run on some data, do the difference in between the data you've already run upon and the new data with:
compareJSON.py --sub <mostRecent.json> <dataAlreadyUsed.json> <fileForNewDataOnly.json>
- Setup a CRAB job with the file for the new data only. In this example, we're running on the
/MET/Run2012A-PromptReco-v1/AODwith thersanalyzer_JetMET_skimming_Run2012A_cfg.pyconfiguration file. We're setting up a task with around 75 jobs, and we will copy the output to the remote directory/MET_Run2012A-PromptReco_v1_2012May10, which lives insrm://osg-se.sprace.org.br:8443/srm/managerv2?SFN=/pnfs/sprace.org.br/data/cms/store/user/yourUserName/MET_Run2012A-PromptReco_v1_2012May10. Naturally, you have to setup these values for the ones you want.[CRAB] jobtype = cmssw scheduler = glite use_server = 0 [CMSSW] datasetpath=/MET/Run2012A-PromptReco-v1/AOD pset=rsanalyzer_JetMET_skimming_Run2012A_cfg.py total_number_of_lumis=-1 number_of_jobs = 75 lumi_mask=fileForNewDataOnly.json get_edm_output = 1 [USER] copy_data = 1 return_data = 0 storage_element = T2_BR_SPRACE user_remote_dir = /MET_Run2012A-PromptReco_v1_2012May10 ui_working_dir = myWorkingDirName [GRID] ce_white_list = T2_BR_SPRACE
- Do the usual CRAB thing to get the output, but you also want the final report. This will produce a JSON file which resides in
myWorkingDirName/res/lumiSummary.json. This file represents exactly the data over which you ran over, taking into account failed jobs, blocks of data which were not yet available, etc.crab -status -c myWorkingDirName crab -getoutput -c myWorkingDirName crab -report -c myWorkingDirName
- To get the amount of luminosity that you ran over, use the
lumiCalc2.pyscript:lumiCalc2.py -b stable -i lumiSummary.json overview
- You should add this data to the set of data you already ran over. You do this by merging the JSON files. The syntax is:
mergeJSON.py previousData.json dataYouJustRanOver.json --output=totalData.json
What should I use for this skimming step?
Naturally, it depends on your specific analysis channel. Remember that the goal is to separate the analysis hierarchically - run over large datasets using the GRID, preselect/reduce them to more manageable sizes, bring them to SPRACE and run the rest of the analysis more or less locally. If you make a very complicated preselection in the GRID, it starts to become comparable to make the whole analysis there, and defeats the whole idea. So, some general points:- You can skim on trigger bits. To do that, you use the
TriggerResultsFiltermodule. You can see an example of trigger-based skimming in this link.
- You can skim on basic RECO quantities. You use normal EDFilters for that. For inspiration, you can look at the official CMS skimming page. Notice that those are the official skims - what we are doing here is mimicking that scheme.
PATtuple making
In CMS we use the Physics Analysis Toolkit (PAT) to steer our analyses. It is a set of standard EDModules and configuration files that act as building blocks for you to build you analysis.SpracePackage
The SPRACE Package is acessible in GitHub and contains some code used for the EXOTICA analyses in SPRACE. See: https://github.com/trtomei/SpracePackage

| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
Slide1.png | r1 | manage | 125.6 K | 2012-05-14 - 18:57 | ThiagoTomei |

{kind=link}
{kind=link}
Ideas, requests, problems regarding TWiki? Send feedback